GitHub Gist
Used to create Random Walk, time-series CSV files larger than the available RAM.
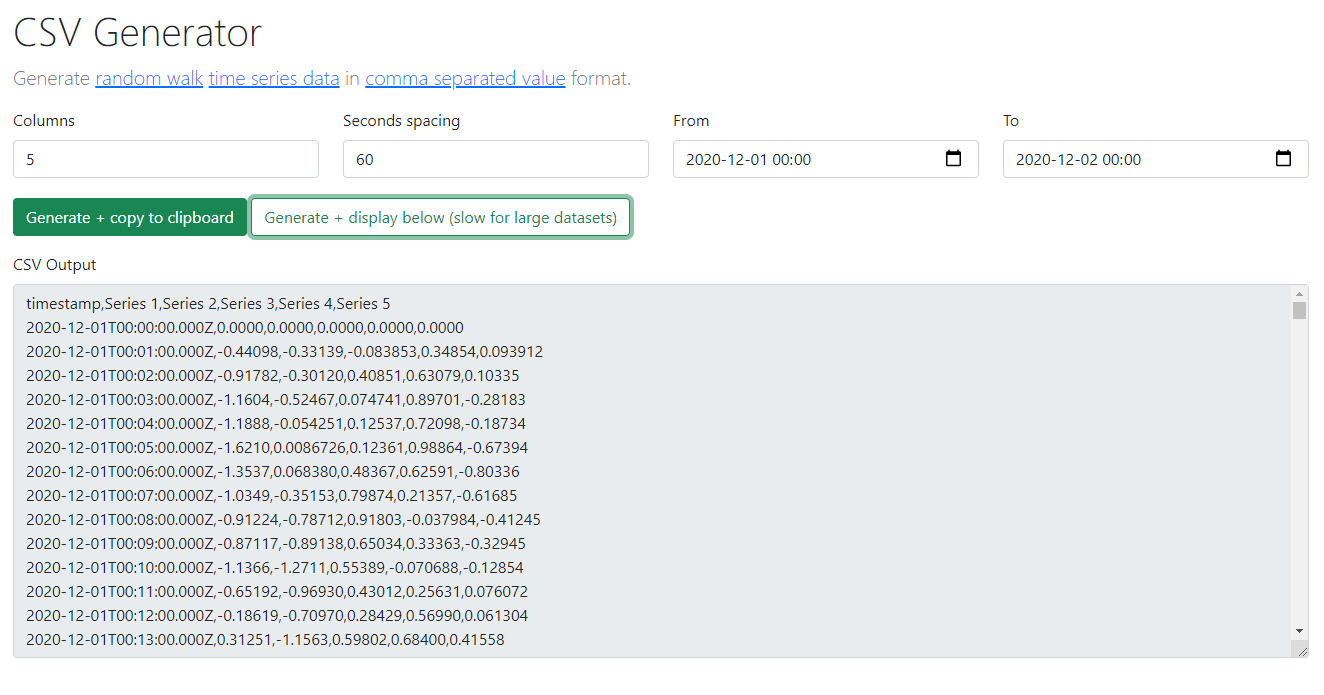
Creating files larger than RAM
In a previous post I included code and a webpage to create random-walk time-series CSV files. Those code samples are only capable of creating CSV files that fit in memory; that is to say if you have 4 GB of RAM you will only be able to create CSV files less than 4 GB in size (after accounting for the operating system and other processes).
Backpressuring in Node.js streams
Node.js streams can account for this build-up of data that can occur in streams using a system called backpressuring. This allows a stream to send a “slow down” request to the source of the data.
By modifying the original CSV generation script, the code will only generate values as quickly as the machine can write them to disk. The key line is the pausing of the stream:
1 | // if false, there is backpressure from the stream - stop sending new data |
if the writeStream.write() returns false, then the write buffer is indicating a data build-up and would like the stream to be paused so it can “catch up”.
Usefulness of the script
This script allows the creation sample CSV files any size - much larger than the RAM available on the computer running it. This is useful for creating large CSV files to stress-test programs that process files larger than the memory available.